Excuse me for not quoting you: @BHAYT, @platypus, but I can’t find a convenient starting point.
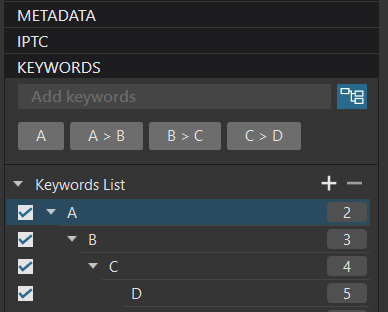
In mentioning storing keywords in DOP files, I was trying to point out that what they hold is decidedly minimal and that, whereas it is possible to reconstruct a keyword hierarchy from the database, it is not always possible so to do from a DOP file.
Which leads me to pose the question - why does DxO put anything to do with metadata in DOP files?
At the moment, metadata can be found in up to four places…
- An image file itself (RAW or not) although PL doesn’t write it there.
- An XMP sidecar for a RAW file
- A DOP file
- The database
At which point, I need to dig up the spectre of SPOD.
In my app, I can say that I only ever store metadata in one place - either the image file or an XMP sidecar. I do not manage a database.
Well, I might not manage a database but macOS does - it’s the Spotlight search engine, freely provided as part of the operating system. It is constantly being updated and indexed all the time that the OS is running.
So, when I write metadata to files, be they images or XMP sidecars, Spotlight duly, automatically, adds those metadata to its database. When I want to search for files that match (a) certain keyword(s), my app submits a predicate to the Spotlight engine and it returns every single file that references it/them.
My point is that, in order to be able to search for files, one first has to add metadata to search for, to some kind of database.
Now, if they wanted, DxO could leverage the same database technology for the Mac version and completely do away with overloading their image editing database but, unfortunately, Windows doesn’t have such a powerful mechanism.
So, it would appear that DxO have decided to implement their own database, presumably so that they can use the same one for both Mac and Windows - except it is not the same database, it is actually two different databases, one for each platform, as can be seen from the differences in table and column names in screenshots made by Bryan and me.
Both databases are SQLite but the Mac database is, in fact, autogenerated from a Core Data object model but I can’t tell what was used to create the Windows one.
All this raises several questions like…
- Regardless of platform, why integrate metadata in the same database as image editing data, when separating it out would provide for greater flexibility and speed?
- Why store metadata in any database, for macOS, given that macOS already provides a comprehensive metadata engine?
- Since the metadata stored in DOP files is so inadequate, why bother writing it there in the first place? It certainly can’t be used for searching.
- It is now possible to turn off automatic synchronisation of editing data to DOP files and metadata to XMP files, meaning that, if someone were to trash the database, they would lose absolutely everything - both editing data and metadata.
- The majority of users who want keywording will use XMP sidecars so, apart from needing a metadata database for indexing and searching, why is there any need at all to put metadata in DOP files?
Which leads me to answer question 5.
At present, DOP files are used for metadata because they contain separate data for virtual copies and, in principal, each virtual copy can have its own set of keywords. This is managed by using GUIDs to link the DOP reference to the VC to the database entry for it.
But this is unnecessary duplication, as I have mentioned before, the DOP isn’t used for searching - its only use seems to be as a safeguard. Or it would be if it actually worked.
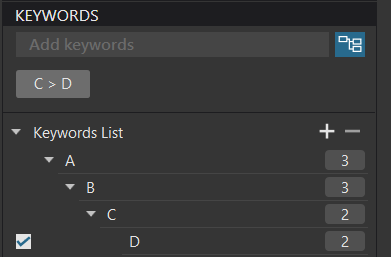
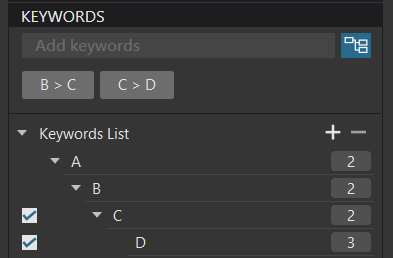
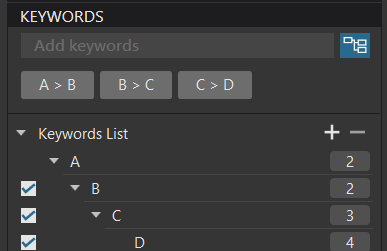
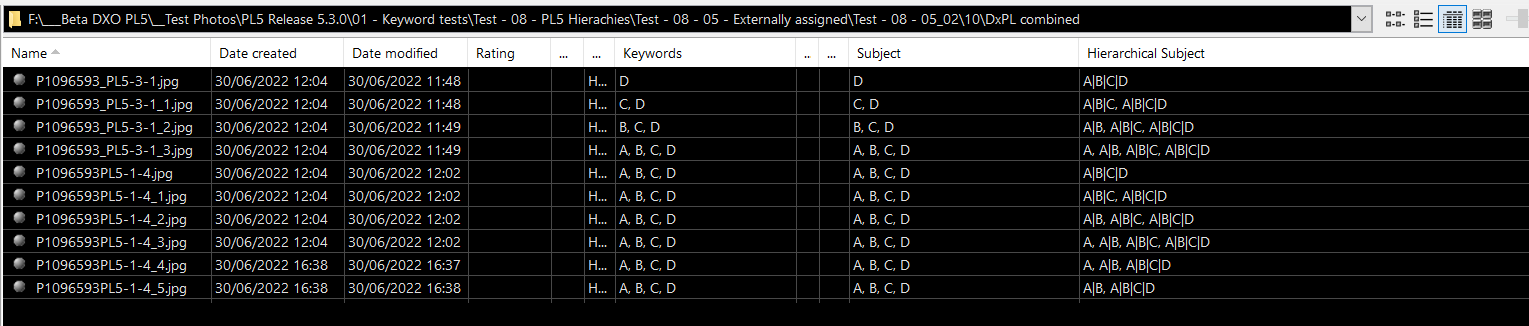
I setup a RAW file with two virtual copies.
I then applied a “matching” hierarchy of keywords to the master and the two VCs…
Assuming that the DOP file would “rescue” me from database deletion, I then closed PL5, deleted the database and restarted PL5.
Well the two VCs were restored fine but the master wasn’t so fortunate…
… even though the DOP contained the Master keyword…
Keywords = {
{
"Master",
},
{
"Master",
"Copy 1",
},
},
…
Keywords = {
{
"Master",
},
{
"Master",
"Copy 2",
},
},
…
Keywords = {
{
"Master",
},
},
On the other hand, instead of “fixing” bugs like this in metadata held in the DOP files, why not take advantage of the fact that’s XMP stands for eXtensible Metadata Platform - something that means that DxO could add their own metadata, like for virtual copies, and dispense with polluting DOP files with metadata.
This still leaves the problem that, outside of PL5, it is not possible to search for keywords applied to virtual copies
I may have answered some of @BHAYT and @platypus remarks here but I daren’t make this post any longer and will address anything specific in another post.