I would tend to agree - although I think I’ll stick with my own app 


Oh, please do.We’d love to be able to sort this out rather than spending days working out what it will take to put PL at the top of the metadata stack 
@joanna the “reason” was the reaction to the two topics I highlighted in my post above. I think that they took one more seriously than the other and “matched” an IMatch option.
What I consider DxO failed to understand was that no amount of “fiddling” would solve the “problem” when the solution was to find a way to leave users metadata absolutely, utterly, irrevocably, completely intact @Musashi, @Marie, @sgospodarenko!
Whether that metadata met any guidelines or not it was put there by their favourite package/DAM etc. and that was what was in their images and that was what they wanted carried forward BUT what I would conjecture is that you and @platypus and I (and other users) want the ability to optionally specify that we get the “best”, most accurate, most compliant keywords possible or, optionally, very close (without all the intermediate hierarchies)!
But that leaves the issue of what simple keywords should find their way (as if the keywords have any control) into the ‘hr’ fields.
In a post a while ago @joanna we had a discussion about the nature of the PL5 database and the structures ‘Keywords’ and ‘ItemsKeywords’ and I wrongly stated that because ‘Keywords’ contained all the keywords in a “flattened” state it should be easy for a search to work only to discover more recently that the “discovery” was “gated” by the ‘ItemsKeywords’ contents (or “missing” contents) which is determined by “assigned” keywords.
I also concluded that DxPL simply took every keyword in that structure to be a candidate for the ‘hr’ data, whereas the preferred strategy is that it should be a (potential) candidate for the ‘dc’ fields and only for the ‘hr’ fields when it is the top item in an hierarchy.
The reason that ‘ItemsKeywords’ is so important is because it is the link (the only link) between the ‘Items’ structure (holding the image) and the ‘Keywords’ structure which holds the various combinations of keywords that have been entered into PL5 or detected in the incoming image metadata as a series of “flattened” keywords.
It actually provides a link from ‘Items’ to ‘Keywords’ (needed for displaying and for creating the metadata) and ‘Keywords’ to ‘Items’ (and to ‘Sources’ and thence to ‘Folders’).
Nowhere is the origin of the keywords maintained/retained, e.g.
- ‘dc’ or ‘hr’ or both
- Image or DxPL
so reconstructing the metadata for output back to the image or into an export is solely based upon the contents of the ‘ItemsKeywords’ and the “algorithm” that DxPL “chooses” to apply at any given time!?
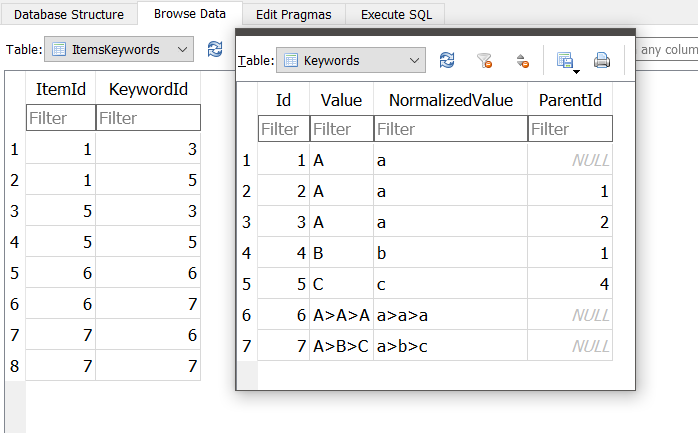
Item 1 has two associated keyword at 3 & 5;
- 3 points to A which points to 2 (A) which points to 1 (A) , giving A<A<A (or A|A|A or A>A>A)
- 5 points to C which points to 4 (B) which points to 1 (A), giving C<B<A (or A|B|C or A>B>C)
Once keywords are in DxPL ALL keywords are either simple or simple but part of a tree structure from the leaf upwards not top downwards.
However, once the keywords are deconstructed and stored in the ‘Keywords’ structure as simple keywords with pointers to re-establish hierarchical keywords from the bottom up (leaf back to tree) all keywords are the same except that there will be entries for the simple ‘dc’ keywords (if any existed) from the image metadata!. These entries are not actually present in the metadata entered into DxPL unless explicitly entered by the user or “assigned” from the list! .
I wrote but never posted (I think never posted) that the “algorithm” for completing the metadata was
-
For every keyword in the ‘ItemsKeywords’, potentially only 1 for Win 10, follow the pointer to the keyword in the ‘Keywords’ structure.
-
If that keyword is not part of an hierarchical keyword chain then output the keyword to the ‘dc’ fields and this is where I feel that PL5 (and the other products) are going wrong because they output a simple keyword to both the ‘dc’ fields and the ‘hr’ fields.
-
If the keyword is part of an hierarchical keyword chain then output the keyword to the ‘dc’ field (this action is now modified by PL5.2.0) and begin to reconstruct the hierarchy. When the hierarchical keyword has been reconstructed output to the ‘hr’ fields + add the topmost keyword of the hierarchy.
-
Repeat for every keyword in the ‘Keywords’ structure for the given image. If this was executed as written it would automatically create the structure that Capture One creates (or very close).
-
At this point there should be one ‘dc’ keyword for every keyword in the hierarchy and both the ‘dc’ entries and the ‘hr’ entries should then be de-duplicated (I believe).
-
Output the “perfect” set of keywords but that will be completely ignoring the exact combination that came in from the image!!!
At a cost unless bought as part of a package from some U.K. camera dealers (£120 I believe), i.e. £209 or £107 for first year(?) or £24.00 monthly.
Arguably that’s what I have been trying to get DxO to do since I started Beta Testing PL5 well over a year ago (when I essentially knew nothing about keyword handling but things didn’t look “right” even then) but hey … head + brick wall!
This is point on which I both agree and disagree at the same time
The first part is an absolute, as it confirms what the MWG guidance states, in order to maintain interoperability.
The second part is something I have argued over with myself (and others) many times. In principal, only one entry for each hierarchy needs to exist but…
It can be argued that each keyword in the “path” can be regarded as requiring full definition; thus the idea of having one definition per node in the hierarchy…
A
A|B
A|B|C
A|B|C|D
I cannot definitively state this as a requirement but I would argue it is more “complete” in that it implicitly reinforces the idea that all leaf nodes, at all levels, are mentioned in the dc:subject tag.
Thinking about Bryan’s (@BHAYT) comment about adding an “applied” column to the link table, brings me to highlight the MWG way of writing the hierarchical structure using the -xmp-mwg-kw:hierarchicalkeywords tag…
<mwg-kw:Keywords rdf:parseType=“Resource”>
<mwg-kw:Hierarchy>
<rdf:Bag>
<rdf:li rdf:parseType=“Resource”>
<mwg-kw:Keyword>Animals</mwg-kw:Keyword>
<mwg-kw:Applied>False</mwg-kw:Applied>**
<mwg-kw:Children>
<rdf:Bag>
<rdf:li rdf:parseType=“Resource”>
<mwg-kw:Keyword>Mammals</mwg-kw:Keyword>
<mwg-kw:Applied>True</mwg-kw:Applied>
<mwg-kw:Children>
<rdf:Bag>
…
Note that each keyword is defined as a typical tree node, with three nodes, one of which holds any children. So, we have…
- Keyword - the keyword itself
- Applied - whether the keyword was actually selected or whether, like the
Animalsnode, it is only there for reference and completeness, but not actually a keyword that the user was interested in recording - Children - speaks for itself, remembering that each child also contains an
Appliedtag.
Now, Bryan, does that ring any bells with your ideas for the database?
Just had a lightbulb moment.
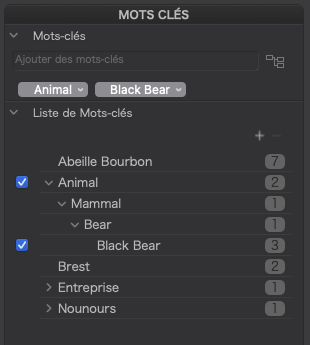
Using PL5, I referenced the hierarchy Animal > Mammal > Bear > Black Bear but I only selected Animal and Black Bear…
Writing this to the XMP gives me…
<dc:subject>
<rdf:Bag>
<rdf:li>Animal</rdf:li>
<rdf:li>Black Bear</rdf:li>
</rdf:Bag>
</dc:subject>
…
<lr:hierarchicalSubject>
<rdf:Bag>
<rdf:li>Animal</rdf:li>
<rdf:li>Animal|Mammal|Bear|Black Bear</rdf:li>
</rdf:Bag>
</lr:hierarchicalSubject>
… with some of the subject keywords missing. It struck me that DxO might be creating lr:hierarchicalSubject entries based on the selected keywords in dc:subject rather than referencing all keywords found in any hierarchies mentioned in the hierarchies, which is what the MWG guidance implies.
It is a subtle distinction but, at the moment, it makes sense, at least, to me.
I remember someone from DxO explaining that they based what they wrote on the hierarchy, during the beta for PL5. This seemed wrong at the time but, looking at it from this point of view, it makes sense and it complies with MWG
Comments? Arguments?
@joanna I have just parked a response that I was writing about a revised design but to answer your query DxPL doesn’t have a clue what is ‘dc’ or ‘hr’ once it is in ‘Keywords’ or ‘ItemsKeywords’!
When it is entered into DxPL is it just a string of simple or hierarchical keywords with no notion of where those fields will wind up. When it reads keywords from the image it throws away any notion of where those keywords came from (part of the proposed (by me) changes I am looking at).
So in both cases it simply starts with a list of keywords from which it “arbitrarily” creates whatever it creates. Hence the excess of ‘dc’ only keywords that wind up in ‘hr’ fields (not an issue exclusive to DxPL).
The assignments do determine what is considered for inclusion but not where they might reside. Hence, my writing out a set of rules because that is all DxPL can use regardless of the heritage of those keywords (entered into DxPL or obtained from the image)!!
Either DxPL requires the preservation of what was where on input (to use or not to use as it chooses) and/or a better algorithm, which is the only thing possible with the current database design!!
I will try to get back to my response later but was trying to help with another topic in my “early” morning slot, now it is back to DIY.
Take Care
EDIT:-
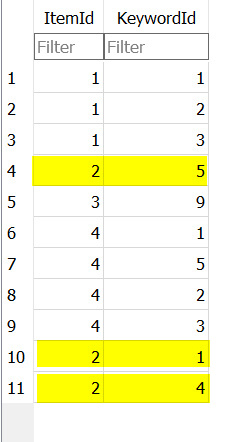
- Cleared db and discovered directory of 4 images with my standard scenario
- Photo 2 contains “animal|mammal|bear” with just “bear” selected on Win 10 by default but no other keywords"
- Selected “mammal” and PL5 completed all selections
- The structures look like this

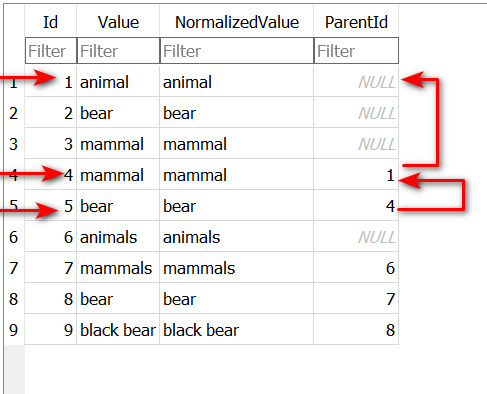
and keywords are constructed by going from ‘Items’ to ‘ItemsKeywords’ and then to ‘Keywords’.
But nowhere is there any indication in the database (no fields to hold the indicators) of ‘dc’ versus ‘hr’ at this point no such distinction is made or maintained!
The result (with all items selected) is
<dc:subject>
<rdf:Bag>
<rdf:li>animal</rdf:li>
<rdf:li>bear</rdf:li>
<rdf:li>mammal</rdf:li>
</rdf:Bag>
</dc:subject>
<crd:CameraProfile>Camera Standard</crd:CameraProfile>
<crd:LookName/>
<exifEX:LensModel>OLYMPUS M.12-200mm F3.5-6.3</exifEX:LensModel>
<lr:hierarchicalSubject>
<rdf:Bag>
<rdf:li>animal</rdf:li>
<rdf:li>animal|mammal</rdf:li>
<rdf:li>animal|mammal|bear</rdf:li>
</rdf:Bag>
</lr:hierarchicalSubject>
Hello Joanna
For example, somebody selected “Bear” and “Black Bear”.
The user expects to see just that 2 keywords.
“Animal” in that case is some sort of category that helps to find the required keyword.
However, there will be “Animal”, “Mammal”, “Bear” and “Black Bear” in a software that uses dc:subject only (or that merges subject and hierarchicalSubject). And there is no possibility to get rid of “Animal” and “Mammal”. They can’t be unchecked in dc:subject
But why?
Bear and Black Bear could just as well be standalone keywords as hierarchical ones.
Not exactly. The complete “definition” of Bear, in the context of the hierarchy we are talking about here, is actually Animal|Mammal|Bear and the complete definition of Black Bear is Animal|Mammal|Bear|BlackBear.
I have previously mentioned there is also another hierarchy for Beer > Craft Beer > Black Bear.
How does the user know which hierarchy Black Bear belongs to if they can only see Black Bear?
Or, if we have another hierarchy for Material > Fur > Bear > Black Bear?
Moving back to my Orange hierarchies - here is a sequence of screenshots of entering five different hierarchical cases for that keyword…
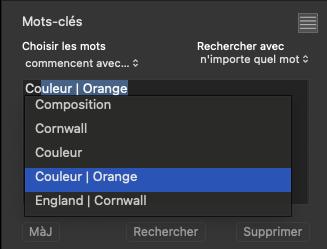
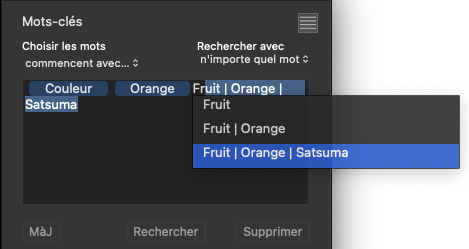
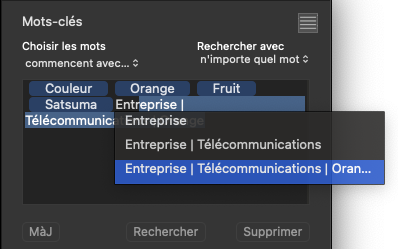
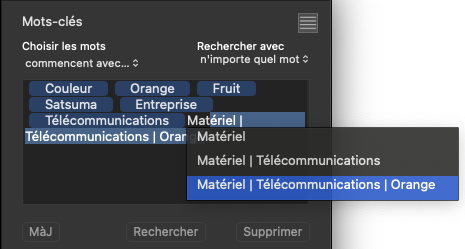
Now, the keywords token field contains…
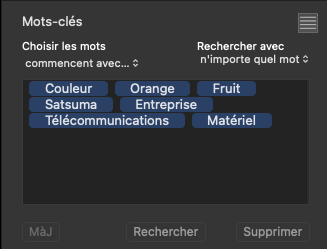
… but the XMP that gets written by my app is…
<dc:subject>
<rdf:Bag>
<rdf:li>Couleur</rdf:li>
<rdf:li>Orange</rdf:li>
<rdf:li>Fruit</rdf:li>
<rdf:li>Satsuma</rdf:li>
<rdf:li>Entreprise</rdf:li>
<rdf:li>Télécommunications</rdf:li>
<rdf:li>Matériel</rdf:li>
</rdf:Bag>
</dc:subject>
…
<lr:hierarchicalSubject>
<rdf:Bag>
<rdf:li>Couleur</rdf:li>
<rdf:li>Entreprise</rdf:li>
<rdf:li>Fruit</rdf:li>
<rdf:li>Matériel</rdf:li>
<rdf:li>Couleur|Orange</rdf:li>
<rdf:li>Entreprise|Télécommunications</rdf:li>
<rdf:li>Fruit|Orange</rdf:li>
<rdf:li>Matériel|Télécommunications</rdf:li>
<rdf:li>Entreprise|Télécommunications|Orange</rdf:li>
<rdf:li>Fruit|Orange|Satsuma</rdf:li>
<rdf:li>Matériel|Télécommunications|Orange</rdf:li>
</rdf:Bag>
</lr:hierarchicalSubject>
Every keyword is recorded perfectly in its appropriate hierarchy and every hierarchical keyword is mentioned in the subject tag, as per MWG guidance.
And yet, the UI in my app has been carefully designed to show the user each keyword only once, along with any keywords in each of their contexts, again, only once.
At present, PL shows a very confusing display should it come across the XMP that my app writes…
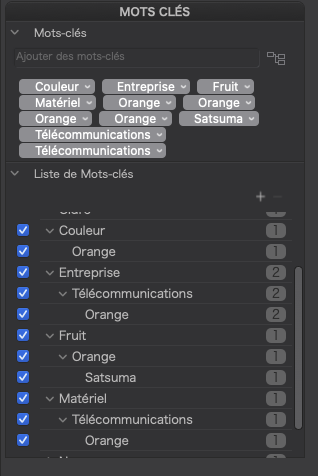
… where keywords in the field are apparently repeated and the only way to determine which is which is to hover over a token to invoke a tooltip.
In actual fact, if the hierarchy view is visible, there should be no need to duplicate the tokens in the token field.
Certainly but they can be unchecked in the hierarchy view, which is what is leading to confusion.
Not that I can see…
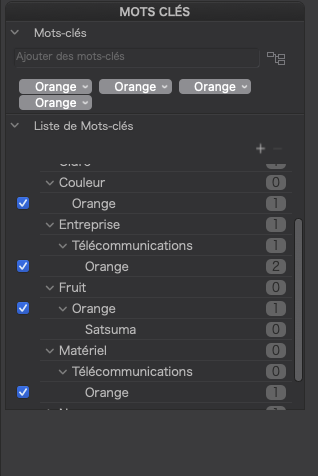
… produces this for XMP…
<dc:subject>
<rdf:Bag>
<rdf:li>Orange</rdf:li>
</rdf:Bag>
</dc:subject>
…
<lr:hierarchicalSubject>
<rdf:Bag>
<rdf:li>Couleur|Orange</rdf:li>
<rdf:li>Entreprise|Télécommunications|Orange</rdf:li>
<rdf:li>Fruit|Orange</rdf:li>
<rdf:li>Matériel|Télécommunications|Orange</rdf:li>
</rdf:Bag>
</lr:hierarchicalSubject>
Whereas, PL5.1.3 (perfectly correctly) writes…
<dc:subject>
<rdf:Bag>
<rdf:li>Couleur</rdf:li>
<rdf:li>Entreprise</rdf:li>
<rdf:li>Fruit</rdf:li>
<rdf:li>Matériel</rdf:li>
<rdf:li>Orange</rdf:li>
<rdf:li>Télécommunications</rdf:li>
</rdf:Bag>
</dc:subject>
…
<lr:hierarchicalSubject>
<rdf:Bag>
<rdf:li>Couleur|Orange</rdf:li>
<rdf:li>Entreprise|Télécommunications|Orange</rdf:li>
<rdf:li>Fruit|Orange</rdf:li>
<rdf:li>Matériel|Télécommunications|Orange</rdf:li>
</rdf:Bag>
</lr:hierarchicalSubject>
@Joanna sorry I forgot the essence of this topic, namely, selection or assignment I got the extra keys because I had selected/assigned “mammal” which automatically selected/assigned “animal” and as a consequence the more “rounded” hierarchical keys were created and the extra ‘dc’ keys along with them.
Removing the selection yielded
<dc:subject>
<rdf:Bag>
<rdf:li>bear</rdf:li>
</rdf:Bag>
</dc:subject>
<crd:CameraProfile>Camera Standard</crd:CameraProfile>
<crd:LookName/>
<exifEX:LensModel>OLYMPUS M.12-200mm F3.5-6.3</exifEX:LensModel>
<lr:hierarchicalSubject>
<rdf:Bag>
<rdf:li>animal|mammal|bear</rdf:li>
</rdf:Bag>
</lr:hierarchicalSubject>
</rdf:Description>
</rdf:RDF>
</x:xmpmeta>
A very slimline, non-compliant set of keywords!
@amikhnev I have real problems with this statement ““Animal” in that case is some sort of category that helps to find the required keyword.” I “hate” the fact that Photo Supreme appears to be “obsessed” with the notion of Category and inserts “Miscellaneous” as the first keyword as a “Category”.
Arguably every keyword in an hierarchy is a (sub-)category until you arrive at the final keyword and that may actually be another (sub-)category where you have just stopped with the granularity of the classification!
While I understand what you say and that could be the reason that the current search works the way that it works when an hierarchical keyword is added. But regardless of the selection/assignments made by the user an hierarchical key exists and will be placed into the ‘hr’ fields with all the keywords in place, including the keywords not marked as selected (assigned) by the user.
This selection will influence the presentation of the keywords in the UI including showing the selections already made, and the contents of the metadata that will be written back to the image (if “allowed”/forced by the user) and the metadata that will be placed in the exported file and, currently, the results of any search, the reason for this topic.
I am no metadata expert but if the keyword will inevitably find its way into the metadata because it has been explicitly assigned or because it is part of a larger hierarchical keyword and therefore implicitly assigned, I personally believe it should be found in a search otherwise the search is being selective and distorting (not) the truth!
However, the default for Win 10 (at least on my machine) is that only “black bear” will be assigned. If I then assign “bear” DxPL will the automatically assign all keywords in the hierarchy. In addition, if all have been de-selected then assigning “black bear” will actually assign all in the hierarchy automatically (which I believe if the default for the Mac version of the product)!?
So I tested the following by selecting and deselecting keywords (but my first attempt at inserting a table was crushed by the post software being used)!
animals X X X X
mammals X X - - X
bear X X X X - -
black bear X X X X - X X X
which should look like
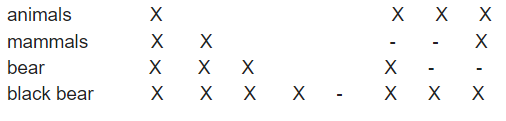
and I exported for each option in the above table and the results are as follows for PL5.3.1:-

The same combinations for PL5.1.4 results in the following;

The problem is assignment will not only condition the response to a search (wrongly in my opinion because it should include implicit assignment as well as explicit assignment) but also the metadata (keywords) output to exported JPGs and available to be written back to the image metadata etc…
If the design of the ‘ItemsKeywords’ structure was ‘ItemId’, ‘KeywordId’ and ‘Assigned’ @Musashi instead of just ‘ItemId’ and ‘Keywordid’ then every ‘Keyword’ for an image (which are stored in the ‘Items’ table in the database) could then be entered into the ‘ItemsKeywords’ database table when they immediately become candidates for searching.
So we would go from 1 entry in the default case on Win 10 (for “black bear”) to 4 entries, one for each of the keywords with each of the entries for “animals”, “mammals” and “bear” having a ‘N’ or ‘0’ (or whatever) in the ‘Assigned’ field and the entry for “black bear” would have a ‘Y’ or ‘1’ (or whatever) in the assigned field.
The UI and the metadata insertion code would now use the ‘Assigned’ field rather than the physical presence of an entry in the ‘ItemsKeywords’ table to do their respective tasks.
But now a search would retrieve all the keywords associated with the image, both implicitly and explicitly assigned. If users wanted to retain the existing way of working there could be (at least) two ways of handling that:-
-
In the search return all keywords in the count field (and pointers to the images) and add an additional entry for those explicitly assigned (selected) in the line below.
-
Add an additional selection box in the search to return only assigned keywords.
But surely that is the job of any software that subsequently encounters the image, now or in the future.
Limiting the potential for future searches is “short-sighted”, it is the job of any software that encounters that image to offer the ability to allow you to search on “animals” (broad though that category may be) but give you the option to never put such a search into the software because that item is “merely” a category with way to many entries but that is where AND (and OR!?) searches come into play.
“Tailoring” keywords is a “slippery slope”, better to have too much data and software that allows you to navigate that, than to throw data away (once it has been removed it can never easily be replaced automatically - not entirely true because software with dictionaries etc. can find the missing data and restore it).
The problem with PL5, in my opinion, is that it currently restricts the search potential by virtue of the explicit assignment! There should be no such restriction, other than my “desire” to enter “animals” into a PL5 search or not, for both explicitly (currently available) and implicitly (currently missing) assigned keywords @sgospodarenko !
1 Like
Indeed
It has to be remembered that “Category” is another concept, in addition to “Keyword”. According to the MWG Guidance…
Categories
The perceived motivation for categories is to have nodes in the hierarchy that serve only to help organize the keywords. The applications that support categories (Adobe Lightroom and Photo Mechanic) do so by allowing any node to be called a category instead of a normal keyword. For example, “States” might be called a category. In that case, searching for “States” might not be allowed and metadata embedded in a file might only mention “Places” and “Wyoming”, leaving out “States”.
Categories are intended as an organisational feature for the keywords dictionary, rather than a valid metadata item. Their purpose is to aid the user in the selection of keywords and they are not intended to be written to the XMP.
Confusing hierarchical structure with categories will only end up polluting the XMP.
There is also the issue of possibly providing a means of importing publicly available keyword lists, that include, not only, categories but, also, synonyms. I am working on such a mechanism for my app but, at the moment, I have had to “convert” categories to top-level keywords and synonyms to sub-keywords. To do anything more would mean having to redesign my keyword management window - something I am not prepared to do yet.
For reasons like this, I would highly recommend that DxO gets to grips with just writing correctly formed hierarchical keywords before daring to move into the realm of categories and synonyms and, with that possible future in mind, avoid using “category” in these discussions.
This is essential to good metadata definition and is one of the reasons the MWG hierarchical tags include the Applied key.
I still feel it would be a far better idea to separate out keyword management into a separate window, thus avoiding the confusion the current UI introduces of trying to simultaneously define and use hierarchies.
I sort of understand and, if I have understood correctly, agree.
If you mean that checking Black Bear when nothing else is checked causes the entire hierarchy to be checked, then that is certainly what the Mac version does. In fact, checking any (sub)keyword, at any level, causes all its “parentage” to also be checked, but not its children.
The action of automatically checking the hierarchy above a selected node is absolutely correct, in order to ensure the correct recording, not only of the lr:hierarchicalSubject but, more importantly, the dc:subject tags.
But then the user is allowed to “undo” that “good thing” by being allowed to deselect parents one by one, in ascending order.
You need to look up how to use tables in Markdown
| animals | X | X | X | X | ||||
| mammals | X | X | - | - | X | |||
| bear | X | X | X | X | - | - | ||
| black bear | X | X | X | X | - | X | X | X |
Here is the “code” for the above table, surrounded in a “code block” to avoid it being formatted.
||||||||||
| --: | :-: | :-: | :-: | :-: | :-: | :-: | :-: | :-: |
|animals|X| | | | |X|X|X|
|mammals|X|X| | | |-|-|X
|bear|X|X|X| | |X|-|-|
|black bear|X|X|X|X|-|X|X|X|
Can I please repeat my example of wanting to search for a “theme”, as in my Orange hierarchies, where the word Orange can appear at multiple levels in the different hierarchies?
My software copes perfectly with such a search, simply because I structure my metadata to mention all members of a referenced hierarchy in the dc:subject tag and provide a search mechanism that allows both AND and OR combined predicates.
That’s, sort of, what I have been trying to get across ever since the PL5 beta. Until metadata is correctly written and managed, searching will never grow beyond its current woefully limited state.
After all, why bother going to all the trouble of writing keywords if you can’t search for them?
@Joanna Thank you for the tutorial on “categories”, I think. I am having enough problem with explicit keywords now we have either “hidden” keywords or “overloaded” keywords, i.e. ‘Arkansas’ also “carries” a keyword of “Country = USA” and “State”, just watch the use of “Paris” hence the expression “Paris France” but “Paris USA” would run into problems because there is more than one it appears!
One problem with the current lack of database management commands is that the preservation of ‘keywords’ and here I don’t mean those that are actively in-use but arguably all the keywords that I have ever entered are not but worse cannot be preserved.
When a command is available to create a new database @Musashi the opportunity exists for the software to carry over certain key (pun semi-intended) data from one database to the new database, e.g. a list of all the keywords ready for me to select from with my new database. Currently all is lost between generations of DxPL databases without explicit commands to create a new one (and preserve the old one with a chosen name), except by “destroying” it (typically with a name change rather than a deletion!)
Yes but they must realise the resistance that exists to having “too many”/“not the right keywords”/“not my keywords” keywords, e.g.
- Why are there so many ‘dc’ keys?
- Why do I have all the hierarchical combinations/too many ‘hr’ entries?
- Why is my data not exactly like Photo Mechanic, Capture One, Lightroom, Photo Supreme, IMatch (please choose an option) etc. given that most of the software packages have different options that can affect their output anyway! Matching a specific package is difficult though not impossible(!?) (let alone the variations from the options selected) but leaving the keyword metadata intact is possible (I believe) as I suggested with the export option @Musashi by taking it straight from the image to any exported images (as one option).
The forums have numerous posts using any and all combinations of the above as a reason why DxO should have left metadata handling to the “experts” and why the current DxPL metadata handling should be left alone (boosted by the complaints about lost ‘Rating’ and ‘Rotation’ and ‘Tag’, i.e. PL5 wantonly loses metadata “randomly” @sgospodarenko) .
Nothing loses anything “randomly”, it typically does that with “malice aforethought” thanks to the design and the coding, i.e. wrong coding right design, right coding wrong design, wrong coding wrong design and for “wrong” you can read “misguided” with respect to design!
I want to use DXPL metadata handling because it is one of the easiest to use (and I have tried a few during my testing of PL5) so getting it to produce the right output is important to me; preferably with some options to restrict all the outputs that can be produced - look at Capture One versus IMatch in my spreadsheet table for an idea of the scope for difference, but assignments could be used to control that but then assignments must not restrict searching as I have outlined earlier.
However, @Musashi I do not want to have to select all assignments for each image so I believe there should be options for;
- PL5.1.4 keywording - one variant of IMatch)
- PL5.2.0 keywording - another more restricted (wrong) variant of IMatch
- The current default Win 10 automatic assignment of the ‘leaf’ keyword only
- The current default Mac assignment (I believe) of all intermediate levels in the hierarchy
to be assigned to all automatically or an image or selected images on demand. Arguably this then requires an additional flag somewhere if 1 and 2 are to be applied as I said to an image or selected images on demand. Items 3 and 4 affect entries in the ‘ItemsKeywords’ structure and the code is already in place to adjust the table entries as those options are manually selected and de-selected.
1 Like
Heheheh. As I’ve already mentioned somewhere else, I have been doing this metadata stuff for nearly four years now, as the heart of my own app. And I have read countless documents on how to, how not to, etc, in order to try and create an app that writes metadata that is truly compatible to everything else out there.
But then, during a chat with @platypus, he mentioned that my app couldn’t yet import a user’s existing keyword dictionary. Oh boy! Was I in for a surprise?
He pointed me towards some readily available dictionaries that were available for downloading and I set about “reverse engineering” one of them so that I could write the code to import it to my app. Which is when I discovered the “delights” of categories and synonyms. I show an extract from one of these dictionaries in this post
Maybe it gives you some idea why it would be better to concentrate on getting “ordinary” keywords right first 
Unfortunately, this is a result of other app, as well as PL, doing weird stuff to make an “acceptable” UI for keyword entry and display.
The greatest unifying and facilitating factor in managing what gets shown versus what gets stored would be if everyone adhered too the xmp-mwg-kw:hierarchicalkeywords tag instead of “making do” with the, far less expressive, lr:hierarchicalSubject tag that Adobe seem to have enforced as standard. The addition of the Applied tag would make life so much easier.
Unfortunately, not having a Mac, you never got the chance to try out my app.
My vote, not surprisingly, goes for the PL5.1 variant - I don’t know why DxO ever reverted from it.
Just think what I might have done to that!?
They panicked and took jh2103’s mail too seriously instead of looking at the bigger picture, i.e. that many users were less interested in what PL5 had too offer (which it hadn’t before) and they wanted there own DAM’ settings maintained. There is a lot of money and “pride” tied up with the product they have bought and a determination to believe that what it does is right, i.e. vindicating their choice.
Because I am in “testing mode” right now I have no such “vested” interest and treat them all with “contempt” until they prove me wrong.
I regards to hierarchical keywords, DPL 5.1.3.55 is probably the most cooperative and I’m back to it again. If we just could get DPL 5.1.3.55’s keyword module in DPL 5.3.1.69…
1 Like
As do I but I am trying hard to get DxO to adopt the professional standards of not chopping and changing and taking users up and down blind alleys but rather of preserving what has gone before as an option (not a replacement)!
PL5.1.4 is still installed on my Test machine alongside PL4.3.6.32.
With your analytical skills, you would make just the kind of beta tester I would appreciate.
Certainly what I see is a “knee-jerk” reaction to one use case, which seems to have messed up things for other cases.
And I think this is possibly the key. More precise options for metadata handling rather than the overly simplistic “automatic or nothing” that we now have - possibly a dedicated panel in the preferences?
I’m about to start drawing up a list of options and will let you and @platypus know what I intend before publishing it, in order to avoid confuddling this public thread too much.
DxO seem to have an aversion to providing “options”. The fact that there are two versions and multiple languages means that a potentially “simple” change can result in a lot more work when it is “externalised” in a UI option! Plus options mean more paths in the software and more paths mean more testing and more opportunities to engineer bugs, which means more regression testing which means …
BUT it allows the differing demands of different “groups” of users to be “met”, providing you really know what those demands are and providing you can get a concensus!
The forum provides a means to elicit opinion but there can be way too much ego, some of it truly personal and some of it “blaming” a feature/quirk of the product where the actual problem is “just” bad coding or poor design (and the term poor has to be considered because “poor” compared with what, what is the “gold standard” against which the product should be compared and found “wanting”).
The work I did on the spreadsheet was a bit of an eye-opener because there was good and bad elements in all the products I tested and I had not expected such variation between the “heavyweights”. The one I have that I feel needs to be included is Photo Supreme and it is omitted because I can’t wrap my brain around its use of “Categories” and putting ‘Miscellaneous’ into a hierarchy is beyond my comprehension but I do need to understand PS so that I can include it in the “league” table.
DxO should have asked all the users to enter a set of data into their DAMs etc. during Beta testing and submitted the results for analysis but that means a co-operative effort!? When they start listening we get the overreaction of the “slimming” down of ‘dc’ fields in PL5.2.0 and the reversion to the DOP as a source of input data (a return to the PL4 way) with PL5.3.0 but both as a non-optional change, i.e. you must like-it or lump-it or find a work-around.
The DOP change was returning to a previous regime but with the DOP now carrying a vast amount more metadata which effectively bocks the metadata from the image, albeit the user can use the ‘Read from image’ command but is that written anywhere.
Edit:- changed illicit to elicit though I fancied an illicit opinion - thanks @Joanna
This was actually stated by one of DxO staff members somewhere in the forums quite some time ago. They actually want as few options as possible but no reasons were given.
Well, in principle, PhotoLab has a common core of functionality, that is written once and then “connected” to the two UIs. Things like metadata options should only need declaring once, so that cuts out the possibility of platform dependent differences. Of course, it would help if the preferences dialog actually looked the same on both platforms
At one point in time (PL5.1.3/4) the XMP written was perfect when compared to the “gold standard” of MWG guidance. This is what I based my app on and proved it is the most compatible for working with more than one DAM. By using this “standard” PL5.1.3 was also completely compatible with Capture One.
I think what most people find “wanting” when they come to apps like PL5, CO and my app is the ability to enter hierarchical keywords in, what one might call, a freeform style, without there being any verification of compatibility.
e.g. Someone wants to be able to enter A|B|C|D in the keywords field of an app and expect the app to make sense of it. Well, some apps do it right, others don’t. I believe it was @KeithRJ who brought this up during the beta, when using Photo Mechanic Plus, where he was able to enter all sorts of “abnormal” stuff into the dc:subject tag, which then confused the heck out of fairly much everything else, not just PL5. The reason - PMP had options that allowed this kind of thing. PL5 tried its best, given how it would have expected to read the metadata but PMP’s ideas created something that PL5 just couldn’t cope with. In fact, the PMP options made it possible to confuse fairly much most software if certain options were chosen.
That could have been a good idea but, if it weren’t for @KeithRJ writing up his use of PMP (with the appropriate options), we wouldn’t have even known about the possibility of his use case. We might even have only had someone using PMP with a different option.
OK. here comes my postulations and cogitations on what “might” help…
-
There should be an option in PL5 to only ever pass through what other DAMs have written, regardless of whether it makes sense, when exporting.
This option should carry a warning that PL5 cannot be held responsible for any input metadata that does not comply with MWG guidance.
Once a user edits the metadata, PL5 should not attempt to “correct” wrongly formatted metadata but should simply make a best attempt to add/remove such edits.
-
If PL5 is the originating DAM, all metadata should be written according to MWG guidance and exported according to the same. This is proven to be readable by everything when written by Capture One, PL5.1.3/4 and my app.
There could be an option to use either the short form or long form for
lr:hierarchicalSubject.Subject - common to both - all keywords flattened…
<dc:subject> <rdf:Bag> <rdf:li>Fruit</rdf:li> <rdf:li>Entreprise</rdf:li> <rdf:li>Orange</rdf:li> <rdf:li>Télécommunications</rdf:li> </rdf:Bag> </dc:subject>Short form of hierarchy…
<lr:hierarchicalSubject> <rdf:Bag> <rdf:li>Fruit|Orange</rdf:li> <rdf:li>Entreprise|Télécommunications|Orange</rdf:li> </rdf:Bag> </lr:hierarchicalSubject>Long form of hierarchy…
<lr:hierarchicalSubject> <rdf:Bag> <rdf:li>Fruit</rdf:li> <rdf:li>Fruit|Orange</rdf:li> <rdf:li>Entreprise</rdf:li> <rdf:li>Entreprise|Télécommunications</rdf:li> <rdf:li>Entreprise|Télécommunications|Orange</rdf:li> </rdf:Bag> </lr:hierarchicalSubject>
So far that makes only two options, or possibly one and a sub-option.
Let me stop there for you guys to tear what I have said apart 