@BoxBrownie There is “no such thing as synchronised” metadata! By that I mean that synchronisation only happens by virtue of the settings of the respective programs that you might be using.
Regardless of the AS setting (AS(AON) or AS(OFF)) the initial “discovery” of a folder triggers the PL5 “import” process (i.e. there is no explicit “import” process) and PL5 executes either the ‘File’/‘Metadata’/‘Read from Image’ command or the equivalent and effectively imports the image and metadata into the DxPL “fold”, metadata included!
So with AS(ON) PL5 is then “watching” for any potential changes in external metadata and, it will execute the ‘File’/‘Metadata’/‘Read from Image’ command whenever such a change is detected and automatically write out any changes made in PL5. For RAW files all such changes will be placed in, or added to, an xmp sidecar file. For JPG, TIFF and DNG the changes will be made directly to the embedded xmp data.
With AS(OFF) no such changes will be imported or exported by PL5 after that initial importation automatically!
With AS(OFF) the process is entirely under the control of the users with the ‘File’/‘Metadata’/‘Read from Image’ and ‘File’/‘Metadata’/‘Write to Image’ commands. These commands can be used at any time with AS(OFF) or with AS(ON) and they are exactly what they state, the data will be read from or written to the image and it will overwrite any data already in place in either that database or the image, depending on the ‘Read …’ or ‘Write …’.
Whether the external programs pick up these changes depends upon the rules defined for those programs and their ability to detect that such changes have occurred automatically.
Even with AS(OFF) PL5 continues with the detection process and sets the ‘S’ icon if any changes are detected that cause a “conflict”. This topic is to request that the icon is set for changes made in PL5 that have not been written to the image and also to indicate the directions of the mismatch > < <>, equivalent to the arrows in LR which are not available with Win 10 PL5.
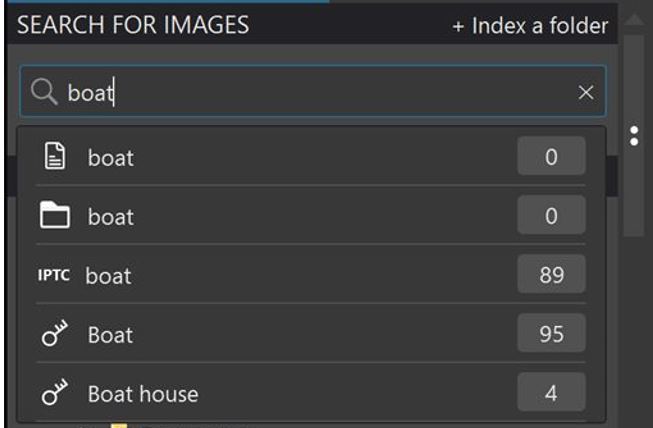
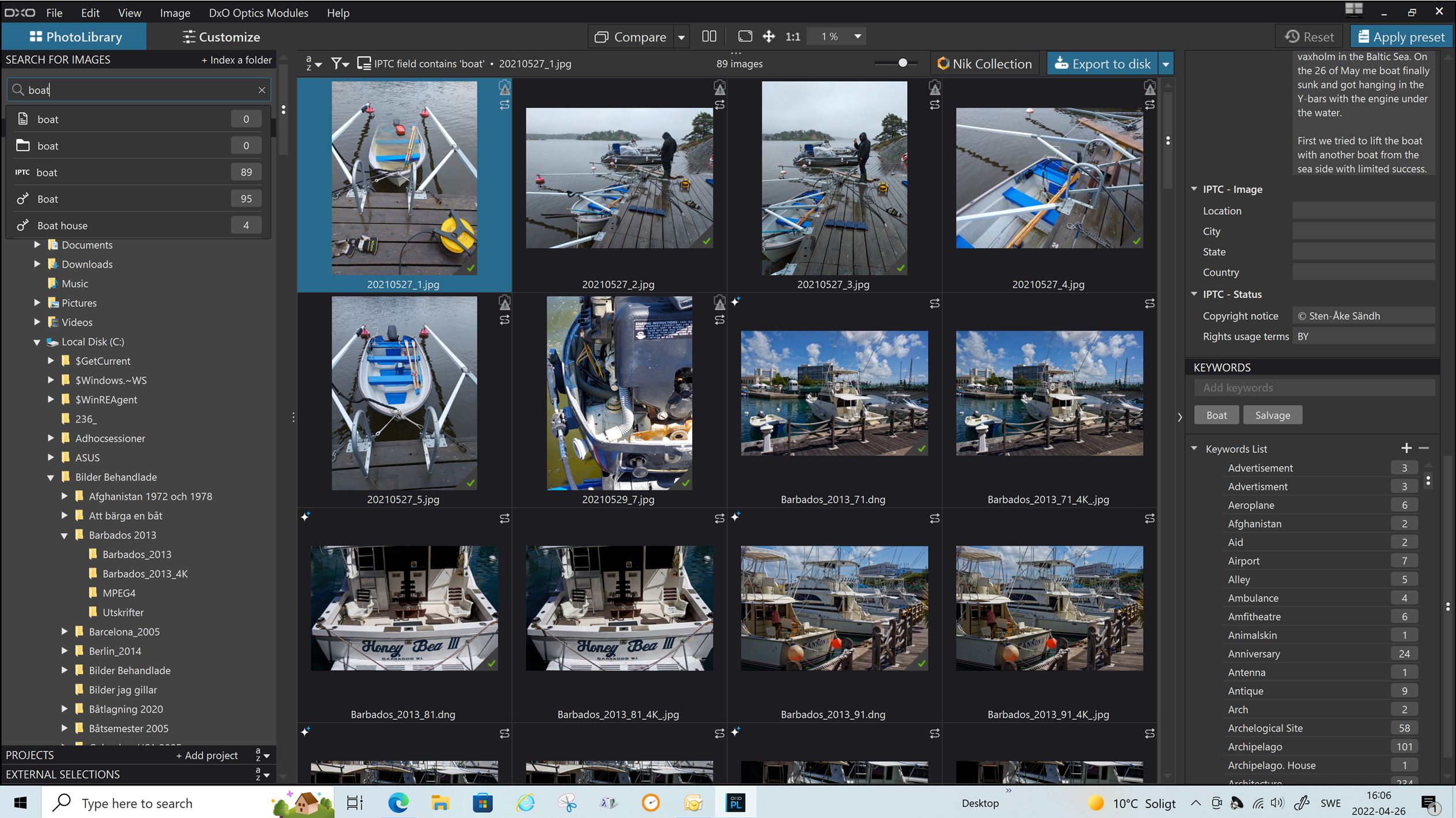
The last issue that needs some consideration that has been discussed at length in a number of posts is not only the communication between programs, essentially via a “post box”, i.e. the image, but also whether is is written in a “language” the recipient can “understand”, i.e, the format of the metadata. It is with the “language” that some concerns have been expressed, even for simple keywords “dog”, “cat” etc. PL5 will set the ‘hr’ keywords to “dog”, “cat” etc. as well as the ‘dc’ keywords and this conflicts (according to those who know way more about it than I) with guidelines that suggest that ‘hr’ data should be restricted to hierarchical keywords e.g. animal|mammal|bear|black bear!
I hope that helps.





 and a real DAM has to offer the users support going either direction. Of that reason DXO also has to provide an interface for exporting and importing keyword vocabularies that people wants to use or already have used with the metadata. If they don´t provide us with that like for exampe Photo Mechanic does, then people will get stuck with a completely proprietary Photo Library and can´t migrate even if they want.
and a real DAM has to offer the users support going either direction. Of that reason DXO also has to provide an interface for exporting and importing keyword vocabularies that people wants to use or already have used with the metadata. If they don´t provide us with that like for exampe Photo Mechanic does, then people will get stuck with a completely proprietary Photo Library and can´t migrate even if they want.