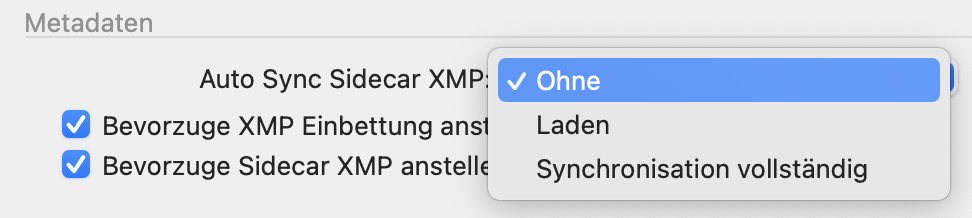
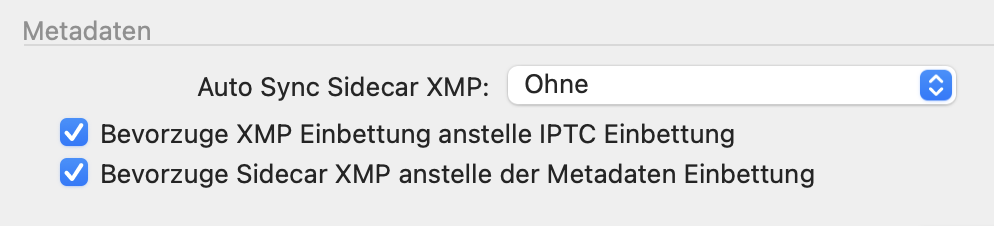
I’d be happier already, if DxO separated metadata read and write as it did with settings sidecars. The current XMP “sync vs. choose&die” approach is just not adequate for an application with higher ambitions.
On the other hand, Lightroom and Capture One do the same thing, C1 with a few options:
Serious metadata exchange would, imo, necessitate
a) a presentation of what the differences actually are,
b) a possibility to select, which of the conflicting data should be used and
c) full bidirectional r/w of non-conflicting metadata (in those cases, where it makes sense).
Under no circumstances should metadata be lost, least of all manually entered items!
Can I be a real pest and ask how you would envisage that happening where people are storing metadata in RAW files, as other software allows it?
I might be an exception in talking about it here but I am certain I am not the only one who uses a RAW only metadata workflow, or are we just an ignorable minority, who will never use PL for metadata in favour of “real” metadata tools?
If we, for the moment, forget where and how metadata can be stored, can we then agree
that metadata reconciliation should be possible in every necessary way?
that reconciliation gets more complicated, when more parties are involved?
I’ve highlighted “necessary”, because this is where differing requirements come in.
Let’s look at the following concept:
Metadata can appear in
the original file (RAW or other supported format)
the first party database (DOPDatabaseV5.dopdata)
a first party sidecar (*.dop file)
a third party sidecar (*.xmp file)
other?
The consequence of the above is, that we’d need an n-way reconciliation. Given the probability that many users have different requirements (which is the important MD-carrier?), the only way to go is, to ask the user, how the reconciliation should be done, and this is not going to be super simple.
Imagine a configurable decision path
If MD in A, then…, else if MD in B…, else if MD in C…, else if MD in D…
IF MD newer in A, then… (can we establish, that a metadata entry is newer? what if an app does not update the MD change timestamp?)
Instead, DxO could pop up a window saying: This MD item exists as red, orange and green, which do you want? This would come as a PITA (not the delicious bread variety) but would allow the user to get exactly what is needed or wanted. This will probably never happen.
Guess, I belong to that ‘stupid’ group of users, who need this kind of (basic) assistance … to put me in the right direction.
Ok, joke aside – when necessary (when things got out of sync) I would like to find an interface which is somewhat self explaining.
And that’s where it starts to get complicated of course
I think that just about sums it up.
Something that keeps on niggling away at me is this MPOD that DxO seems to insist on using.
If the MD is being held in the RAW, or other file format, there is absolutely no need to add it into a DOP sidecar as well. The XMP format (eXtensible Metadata Platform) allows for third-party metadata and can quite reasonably be expected to cope with adding metadata for virtual copies as well as the main image. Such metadata would be totally proprietary and would be simply ignored by any other apps.
If the MD is being held in an XMP file, equally, there is no need to add it into a DOP sidecar as well. Just as with the RAW file, DxO proprietary MD can be stored there for virtual copies.
In case 1 or 2, the only real justification for holding MD in the database is to hold an index of files to speed up searching.
If a user chooses to use only the database, with no DOP files, XMP sidecars should not be necessary for RAW files and there would be no need to write the MD to either the original RAW file or original non-RAW files, as everything can be stored in the database, with MD only being written to exported files. The only exception is if the user wants to send a RAW file to someone who doesn’t store or read MD in/from RAW files, in which case, it should be possible to generate an XMP file to accompany it.
Absolutely. But if we (including DxO) can agree on a clear distinction of possible MD sources and recording solutions, then we might stand a chance of disentangling things.
First imperative has to be a reconciliation dialog that allows the user to choose their SPOD and write the “truth” back to anywhere that doesn’t agree with the chosen source.
At this point, the pest in me has to insist that MD in RAW files has to be a possibility as a source and that, for reconciliation, has to be writeable. There should be no requirement for PL to insist on either writing to DOP sidecars or the database (except for caching purposes) or even adding XMP sidecars, which complicate both the user’s RAW only workflow and reconciliation.
The problem I see is, especially in the case of RAW files, MD can easily be found in two sources - Nikon can add Rating in-camera fro example. As soon as you decide to read and then ignore that, you end up with MPOD with a revised Rating in, at least an XMP sidecar and, straightaway, the XMP sidecar is out of sync with the RAW file, which immediately adds to the complexity of reconciliation.
But, unless I haven’t completely lost the plot, unless all sources can be updated to agree, reconciliation errors will still be present.
Anyway, I have to go out and do the shopping. While I’m gone, feel free to argue amongst yourselves
You’re not lost and yes, errors can persist, depending on where we allow the app(s) to write to. This is also the reason I want DxO to separate metadata read and write.
There seems to me to be only two reasons for storing metadata…
In the original files (or their XMP sidecars)
a. so that images can be searched for based on their metadata
b. so that the metadata can be worked on collaboratively
In exported files so that they can be incorporated in things like image banks.
Or can any of you think of any other reasons?
In any case, apart from speeding up searching, I can’t see any reason at all for storing metadata in either DOP files or the database.
1 Like
Stenis
(Sten-Åke Sändh (Sony, Win 11, PL 6, CO 16, PM Plus 6, XnView))
30
Why a database centric solution isn´t a good idea
I don´t agree at all with number #4 in your text. Of course you are right in the fact that if you use the database as the metadata master like Lightroom always have done, you don´t technically need either DOP-files or XMP-files to store the metadata but then you will live in a “single point of failure” context that I have described above as an uneccessary vulnerable configuration.
One of the most important effects of storing metadata in XMP is that it gives you a much more rubust distributed metadata configuration. In that case each and every XMP-file or XMP-compatible file like DNG, TIFF, JPEG and even textfiles like PDF owns the metadata. If one of these files gets corrupted you will lose that specific file only and the metadata it stored but if you get a corrupted metadata database like the catalog in Lightroom you risk to loose absolutely all of your metadata. If a catalog in for example Photo Mechanic gets corrupted it´s just to reindex since it´s built by reading the metadata in the files. It´s a hell of a difference.
Keep it simple
I think Bryan has done a great job looking at these problems from all sorts of angles but I think his practical recommendations are a little overcomplicated. If users should get overwhelmed by all these different switches I think @platypus “suggestion to DXO” will be a better way forward. If we get a solution where we can choose between two separated automatic sync functions - one for reading and one from writing from and to the metadata containing files, it would be a great start. And in my workflow I want that read data propagated to the database as soon as i open an image library so the database automatically is kept in sync with the XMP in the files. I don´t understand the specific need for any “Add”-versions in the flow since I think “Add” should be “Overwrite” instead. If that modell would be used it would heal a conflict automatically. What I definitelly don´t want is a conflict resolution system that is manual or semi manual. If it isn´t automatic it will ruin your work flows efficiency.
If you don´t like the words “Read” and “Write” we can talk about “Data owners” instead - either an “External system” owns the data or Photolab. When for example Photo Mechanic owns my data I don´t see that it shall be allowed at all to maintain metadata in Photolab. In that case I want DXO to inactivate all the metadata elements in Photo Library. If I should choose to let Photolab own the data then Photolab should overwrite the XMP-data in the images and unlike Lightroom it should also always update the metadata in the files to ensure a possibility to recover after a disaster. Because if that should happen the user just needs to point to the topfolder (remember?) and reindex again and the ones wanting to migrate cound pretty easy index the very same metadata in another system and start to use that instead if that is what they prefer.
Since there is a database in Photolab it has to be in sync with the XMP-metadata in the files. This is extremely important. I have written that DXO has done a fantastic job migrating both the data and creating a flat vocabulary completely automatic out of the non structured keywords used in the files when indexing my XMP-metadata from Photo Mechanic. So it should be very easy to migrate from Photo Mechanic Plus to Photolab Photo Library BUT it sure doesn´t look as great if some one decided to go the other way today and a real DAM has to offer the users support going either direction. Of that reason DXO also has to provide an interface for exporting and importing keyword vocabularies that people wants to use or already have used with the metadata. If they don´t provide us with that like for exampe Photo Mechanic does, then people will get stuck with a completely proprietary Photo Library and can´t migrate even if they want.
Absolutely right. Which is why I would rather have a single point of failure on a file by file basis, rather than one which could wipe out my entire photo collection and it is why I would, personally, like to see that point of failure in individual RAW files, so that the worst that can happen is that I might have to restore that one file from my Time Machine backup
The number of times I have been able to use Time Machine to simply “travel back in time”, to undo a mistake or recover an accidentally deleted file. And the great thing is, I am not limited to something as distant as yesterday, I can go back just an hour if I need to and it’s running all the time without me having to think about it.
Which is maybe another reason why I never worry about editing metadata in RAW files, in addition to the fact that I know ExifTool always creates a safety backup until all changes have been verified.
As things stand at present, I can’t trust PhotoLab to touch metadata for my photo collection. What it does as a standalone DAM is “OKish” but the searching is totally useless. I, like many others will be sticking to my own external solution and not letting PL anywhere near my metadata, especially since DxO refuse to play ball with embedded MD in RAW files.
Nonetheless, I shall be keeping a keen eye on future developments in that field and just hoping DxO will get back to doing what it does well - editing images.
1 Like
Stenis
(Sten-Åke Sändh (Sony, Win 11, PL 6, CO 16, PM Plus 6, XnView))
32
Photolab 5 was a huge leap forward when it came around Christmas 2022 compared to version 4 that really was a joke concerning the metadata support. The only good with version 4 at least was that it managed to pass the metadata unharmed from my RAW-XMP to my JPEG-files.
There are really a few things to like now about version 5. Like I wrote earlier the migration of my XMP-metadata (via the indexing in Photolab) is “almost” fantastic. It both migrates the metadata correctly and builds a keyword list from the keywords used in the image files (with the condition that we use non structured keywords) BUT still there are I think four elements I use in Photo Mechanic that are not transferred correctly and that are the set of elements concerning “Image taken”. I don´t know why that is and I will ask the DXO staff why when I get time. Version 5.2 has got some improvements when it comes to the usage of structured keywords, but still it´s “one way” or from a third party program → Photolab BUT not the other way around.
I´m also really pleased with how well Photolab integrates with Photo Mechanic. It´s really seamless and it also manages to keep and preserve the integrity of both the RAW-files, the DOP-files and the XMP-sidecars when for example moving, copying and reading the image data. For me Photolab and Photo Mechanic Plus together in beautiful symbiosis is a real dream combo when it comes to both image quality and an effective image library work flow.
DXO isn´t Adobe with their comparably abundanat resources and it shows when they have to put in a lot of resouces in developing Photo Library like last year. I guess that has been one of the reasons why it took them four months to develop the camera profile to Sony A7 IV for example. The work to implement the image database had a huge cost at many levels. Not the least in a lot of bad will of different reasons but it might prove to have been a necessary improvement for the future.
Now when most of the things are in place with the Photo Library hopfully DXO will get back on the track which earlier has made Photolab the markets maybe best software when it comes to pure image quality. I hope they will focus now on improving their layer tech. I would like a “magic brusch” like the one in Capture One and also a possibility like in CO to turn a color “picker” selection into a layer. I also want that and the Color Wheel that now just is a “general tool” to be available even i “Local Adjustments”. If I get that as a Christmas present from DXO in eight months it will be my version of nirvana.
Photolab also have to get used to handle XMP written to the XMP-headers of various RAW-files. Please look att this article Joanna:
It´s not just Nikon! Even Sony is writing some of their own metadata right into the RAW-files. This data is really important since it contains “picture profile”-profiles used by the users in the cameras for processing in camera JPEG-files but that is not all. This data is even used in Sonys own “free” RAW Converter Imaging Edge. This metadata is the reason an image might look better from start in Imaging Edge than in Adobe Camera RAW. Interestingly enough things like that are almost never discussed when talking about converters and image quality. I have tried Imaging Edge myself and it is far better than I first thought and one huge benefit is that that software always support Sonys latest RAW-files as soon as a new camera model is released. That is really an important reason why DXO just can´t take four moths to release support for Sonys A7 IV ARW. That will make DXO irrelevent for a lot of Sony users with brand new camera bodies and DXO needs that user base to if they shall be able to keep up with the costs it takes to support R&D financially.
I got that button on a FotoWare event in Berlin five years ago or so and still love it and keep it close to my own heart of different reasons.
One thing I wonder about is that so many seems to just focus on “keywords” when talking about metadata. For me keywords is almost just an internal thing when maintaining my own image library in PM Plus. I think most of my 20 plus metadata elements I maintain are more important than my keywords really for my metadata´s over all impact on my images presence on the Internet.
I also have to say I think it´s nice that I can see in Photolab Photo Library where a search have found the word I was looking for.
Stenis
(Sten-Åke Sändh (Sony, Win 11, PL 6, CO 16, PM Plus 6, XnView))
39
Absolutely but from what I can see with my own images it’s far more important what I write in elements like Headline and Subject or Image Taken or ever in the the foldertext.
Keywords are often so generally used that they just get lost in all the “search noise” the search engines have to handle.
@Stenis, using headlines and descriptions certainly help to improve order, not for the sake of itself, but for easier finding most of all.
Indeed, if we thing of all the images hanging around in the Internet. If we use keywords locally, to find assets in our own electronic shoebox, a controlled vocabulary can improve both search results and ease of attribution of keywords.
If we start out with a) a chaotic collection of keywords, then b) sort and order them in a sensible hierarchical structure and from then on c) attribute keywords from the keyword list instead of just typing (including typing errors) what comes to our mind, we’ll get a fairly usable archive.
Just don’t try searching for this keyword OR that keyword. Impossible
Stenis
(Sten-Åke Sändh (Sony, Win 11, PL 6, CO 16, PM Plus 6, XnView))
42
I don´t know what you are aiming at with that statement.
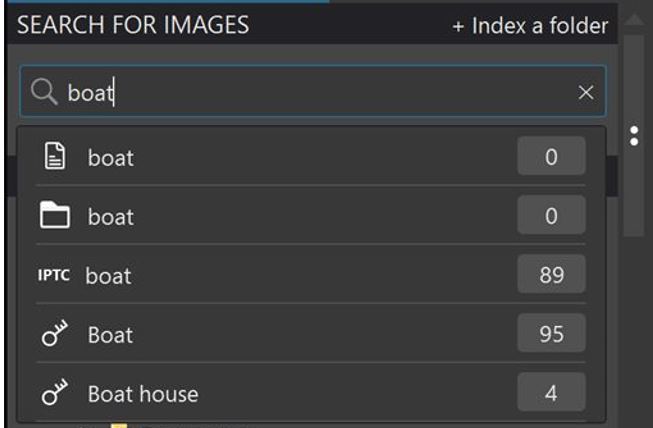
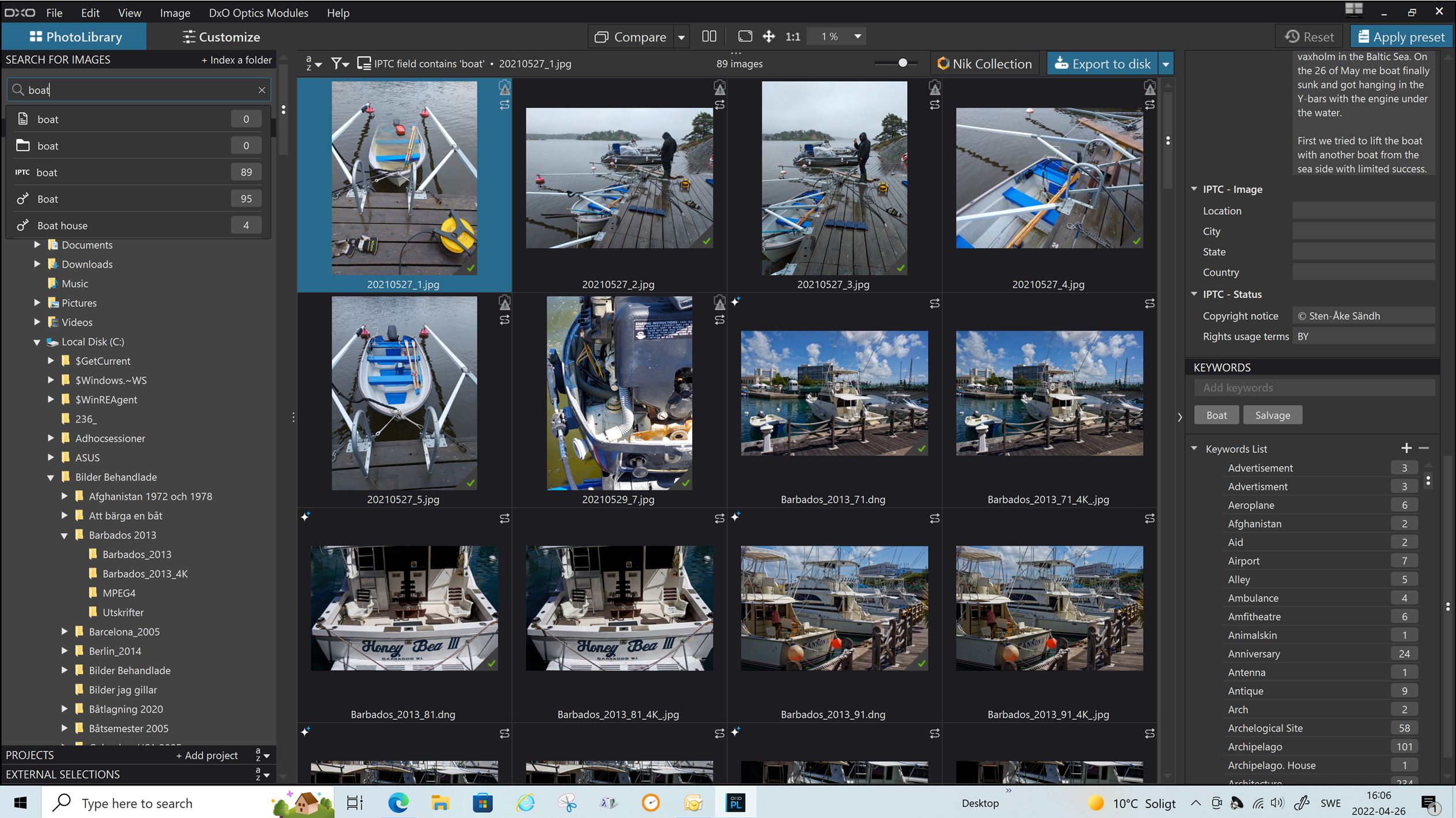
Sure there is not possible to just select a keyword from i list in the main search field and that´s a pity and entering a keyword will not instantly perform a search BUT if I type a keyword in the same field I get a list of proposals: to use the hits in ITPC, the keywords, the folder name or the filename. For every option I get the number of hits - if there are any. If I select one that has hits the search will get performed. Not the fastest and most efficient way to do it but it sure works and as a bonus you get to know where the hits were aggregated from which I sometimes find useful.
It´s not at all useless but just a bit cumbersome.






 and a real DAM has to offer the users support going either direction. Of that reason DXO also has to provide an interface for exporting and importing keyword vocabularies that people wants to use or already have used with the metadata. If they don´t provide us with that like for exampe Photo Mechanic does, then people will get stuck with a completely proprietary Photo Library and can´t migrate even if they want.
and a real DAM has to offer the users support going either direction. Of that reason DXO also has to provide an interface for exporting and importing keyword vocabularies that people wants to use or already have used with the metadata. If they don´t provide us with that like for exampe Photo Mechanic does, then people will get stuck with a completely proprietary Photo Library and can´t migrate even if they want.