Hi,
that’s little bit sad news, but thanks for the information. So we will see during the fall.
Jiri
Hi,
that’s little bit sad news, but thanks for the information. So we will see during the fall.
Jiri
I’ve been editing for half a day and I’m finding the latest release of Photolab (v5.3) with full native Apple Silicon code to be significantly faster to use whilst editing. Images render much more quickly when opened (and zoomed in to 100%). I’m now moving from one image to another without noticing the pause for it to fully render.
Basically, this release has made Photolab a dream to use on a M1 Mac.
Export time seems to be about the same as before, but that had already been optimised for the M1 chips.
This next bit is anecdotal as I never logged the memory useage with previous releases, but now that I’ve been edting with it fo a few hours I’ve realised I’ve not had to restart the app to bring back performance. So my guess is that memory management has improved too?
The same can be said for exporting. Previously if I did an export after editing for a while I found that the export speed was sluggish and after a restart of the app the export performance returned.
I’ve just exported after editing for a while and encountered no such issue.
Thanks DxO team, this is great 
Note: I use a M1 Mac Mini with 8Gb memory and 512Gb SSD, and Nikon Z6ii raw images loading from a 500Gb Samsung T5 external SSD (connected by a USB-C cable).
Thanks for your detailed feedback about the performance boost when working in your typical scenario.
(and thanks for the compliments BTW  )
)
Steven.
I didn’t notice there is a release with full native Apple Silicon codebase available, or I missed any news?
It is PhotoLab 5.3 which was released yesterday.
Mark
Same here, major performance increase in all areas except export/denoising which were already optimised. That’s a big win! Thanks a lot for not making this a paid upgrade in the following version
does this new version take advantage of both sets of ANE core on the M1 Ultra chips?
i definitely like the improved snappiness of the UI when dealing with large numbers of new files in gallery.
not sure how that answers my query.
i am inquiring whether both sets of 16 ANE for the M1 Ultra are utilized.
the m1 mini used by CHPhoto has 1 set of 16 ANE.
I believe the point of the way Apple designed the Ultra cpu was that it would be seen by the OS (and apps) as a single cpu, which navigates around the issue of an OS or application needing to be ‘multi-processor’ aware.
So, I’d be surprised if Photolab wasn’t using all 32 ANE on your computer. But I have no means to test that so please don’t take this as a definitive answer! Just trying to think this through logically…
unfortunately, activity monitor provides no information on ANE usage,
so without the dXo telling us, it’s all just speculation.
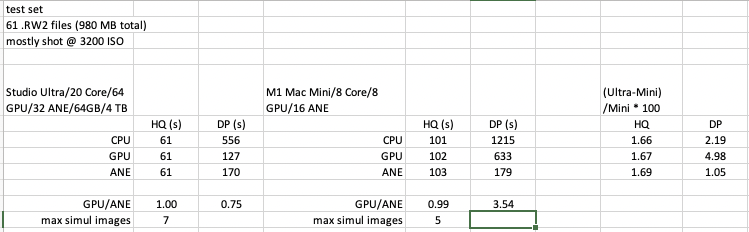
in my own testing of exporting 23 .rw2 files with DP on my M1 Ultra Studio,
selecting the 64 GPU core option was 93 seconds vs 88 seconds for the ANE option
the GPU option was roughly 5% faster
no idea if the ANE option used 16 or 32 cores.
after some testing as suggested by CHPhoto, it appears that PL5.3 only uses 16 of the available 32 ANE on the M1 Ultra, but it sure takes advantage of the extra GPU’s available!
please multiply the numbers in the last two columns by 100!
Nice analysis @Icubed!
I wonder, does anyone on this forum have a Mac Studio with the M1 Max processor inside?
It would be interesing to see how it compares in a test like this to the M1 in the Mac Mini and the M1 Ultra.
I’ve taken the data above from @lcubed and compared how many more cores the two computers have (as multiples, so a computer with 16 CPU cores has a multiple value of ‘2’ when compared to a computer with 8 CPU cores), and then compared the multiple with the export times and then calculated how many multiples the exports were.
The export time ‘multiple values’ I’ve coloured in orange are the processes I’m guessing use just the CPU.
The export time ‘multiple value’ I’ve coloured in yellow is the processes using the GPU.
The export time ‘multiple value’ I’ve coloured in blue is the processes using the ANE.
Takeaways:
I think it is common knowledge that doubling the number of cores in a processor does not equate to double the performance.
(IMO) it seems reasonable that with a 2.5x core count in the Studio that the processes using just the CPU increase in performance by 1.7-2.2x.
The GPU on the Studio has an 8x core count with a corresponding increase in performance of 5x. Could more performance be extracted from the GPU? I feel that a 6-6.5x increase in performance would be more reasonably expected.
The ANE on the Studio has 2x the core count with a near identical performance as the Mini with half as many ANE cores. As @lcubed said, it seems the additional 16 ANE cores on the Studio Ultra are not being used.
I guess the question here is: is this something DxO needs to investigate with Photolab optimisation with the ANE on the Ultra, or is this an issue Apple may have with the way the ANE has been implenmented on the Ultra?
Let’s not forget that the CPU might need to feed the GPU and ANE. However the tasks are being split between these units, the best case will be that the weakest link will determine max throughput - even with the most sophisticated algorithm distributing load between the units. Moreover, not all units can do everything,
If you have no need for rocket fuel, no need to stock more of it in your garage.
True, but why is the CPU not feeding the Ultra’s ANE at the same rate it feeds the GPU?
If the CPU is the weakest link, then surely the GPU and ANE export times with the Ultra would be similar?
I am most certainly not a software or hardware engineer, just a keyboard warrior who is trying to apply some logic to these results to highlight if something can be improved or is amiss somewhere…
Have you tried to run separate batches in parallel?
Canon DPP could be sped up considerably with this trick quite a while ago, but it might make things worse with DPL.
how would one set up batches to run in parallel in PL5?